
目次
データは無限大です。 データサイエンティストは毎日それに対処する必要があります!
データがあり、機能があり、何が起こり得るかを予測したい場合があります。
そのために、データサイエンティストは、そのデータを機械学習に入れてモデルを作成します。
関連コース: Python機械学習コース
例を設定しましょう:
- 写真に猫と犬のどちらが含まれているかをコンピュータが判断する必要があります。
- コンピューターには、その方法を学ぶためのトレーニングフェーズとテストフェーズがあります。
- データサイエンティストは、猫と犬の何千枚もの写真を収集します。
- そのデータは、トレーニングセットとテストテストに分割する必要があります。
次に、分割が発生します。
トレインテスト分割
スプリット
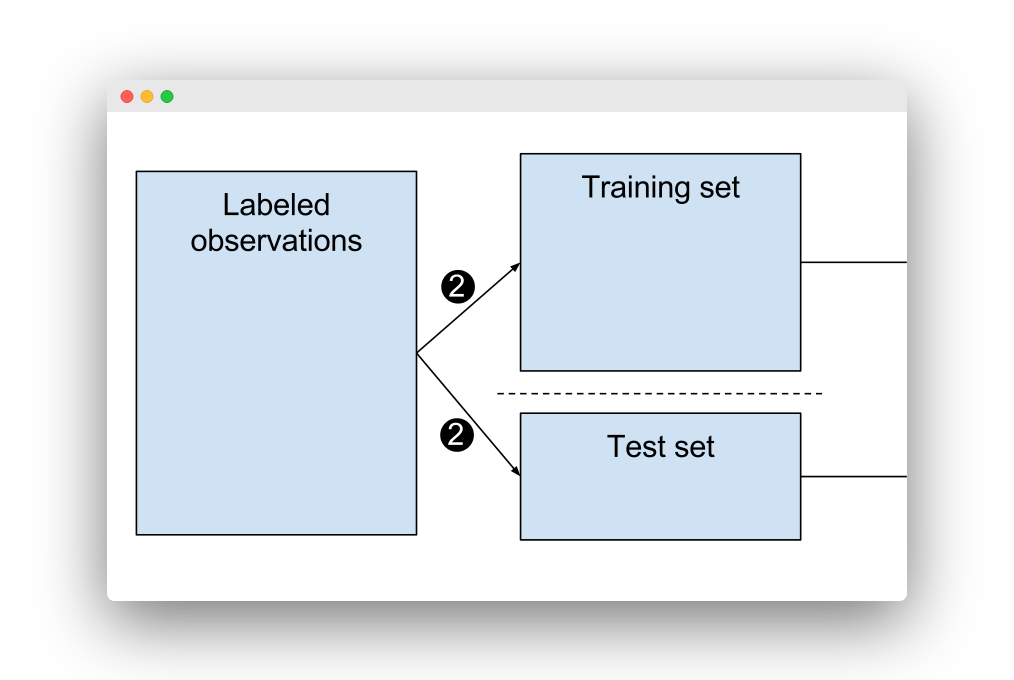
結果が疑わしいため、トレーニングした同じデータをテストできないことを知っています…トレーニングとテストに使用するデータの割合をどのように知ることができますか?
簡単です。2つのデータセットがあります。
- 1つには、(x)と呼ばれる独立した機能があります。
- 1つには、(y)と呼ばれる従属変数があります。
それを分割するには、次のようにします。
xトレイン–xテスト/ yトレイン–yテスト
それは簡単な式ですよね?
xTrainとyTrainは機械学習のデータになり、モデルを作成できます。
モデルが作成されたら、x Testを入力すると、出力はyTestと等しくなります。
モデルの出力がyテストに近いほど、モデルはより正確になります。
1 |
import numpy as np |
次に分割し、テストセット(トレーニングに残っているもの)に33%を取りましょう。
1 |
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) |
次の2つのセットがあることを確認できます。
1 |
X_train |
データサイエンティストは、統計と機械学習のデータを2つまたは3つのサブセットに分割できます。
- 2つのサブセットがトレーニングとテストになります。
- 3つのサブセットは、トレーニング、検証、およびテストです。
とにかく、科学者はモデルを作成してデータをテストする予測をしたいと思っています。
彼らがそうするとき、2つのことが起こる可能性があります:過剰適合と過適合。
過剰適合
過剰適合は過適合よりも一般的ですが、モデルの予測可能性への影響を回避するために、何も起こらないようにする必要があります。
それで、それはどういう意味ですか?
モデルが複雑すぎると、過剰適合が発生する可能性があります。
過剰適合とは、トレーニングしたモデルが「あまりにもよく」トレーニングされており、トレーニングデータセットにあまりにも密接に適合していることを意味します。
しかし、それがうまくいくのなら、なぜ問題があるのでしょうか? 問題は、トレーニングデータの精度が、トレーニングされていないデータや新しいデータでは正確にならないことです。
それを回避するために、データは観測数と比較して多くの特徴/変数を持つことができません。
アンダーフィッティング
アンダーフィッティングはどうですか?
モデルが単純すぎて、モデルがトレーニングデータに適合しないことを意味する場合、適合不足が発生する可能性があります。
これを回避するには、データに十分な予測子/独立変数が必要です。
前に、検証について説明しました。
機械学習を初めて使用する場合は、 それなら私はこの本を強くお勧めします。
検証
相互検証は、科学者がデータを(k)サブセットに分割し、それらのサブセットの1つであるk-1でトレーニングする場合です。
最後のサブセットは、テストに使用されたサブセットです。
一部のライブラリは、トレーニングとテストを行うために最も一般的に使用されます。
- パンダ: データファイルをPandasデータフレームとしてロードして分析するために使用されます。
- Sklearn: データセットモジュールのインポート、サンプルデータセットの読み込み、線形回帰の実行に使用されます。
- Matplotlib: pyplotを使用してデータのグラフをプロットします。
最後に、データベースを分割する必要がある場合は、最初に過剰適合または過適合を回避します。
トレーニングとテストのフェーズを実行します(必要に応じて相互検証を行います)。
必要な仕事により適したライブラリを使用してください。
機械学習が役に立ちますが、それを上手に使う方法が必要です。
Hope this helps!
Source link
