Hadoopは、ビッグデータの処理に広く使用されているオープンソースフレームワークです。 Bigdata / Data Analyticsプロジェクトのほとんどは、 Hadoopエコシステムの上に構築されています。これは2層で構成され、1つはデータの保存用で、もう1つはデータの処理用です。
ストレージはHDFS ( Hadoop Distributed Filesystem )と呼ばれる独自のファイルシステムによって処理され、処理はYARN (さらに別のリソースネゴシエーター)によって処理されます。 Mapreduceは、 Hadoopエコシステムのデフォルトの処理エンジンです。
この記事では、すべてのデーモン(JVMは)CentOSの7日にシングルノードクラスタを実行していることになるのHadoopの擬似ノードのインストールをインストールするプロセスについて説明します。
これは主に初心者がHadoopを学ぶためのものです。リアルタイムで、 Hadoopはマルチノードクラスターとしてインストールされ、データはサーバー間でブロックとして分散され、ジョブは並列に実行されます。
CentOS7へのJavaのインストール
1. Hadoopは、 Javaで構成されたエコシステムです。 Hadoopをインストールするには、 Javaをシステムに強制的にインストールする必要があります。
# yum install java-1.8.0-openjdk
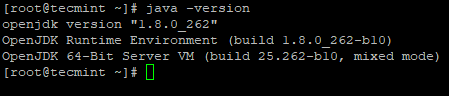
2.次に、システムにインストールされているJavaのバージョンを確認します。
# java -version
CentOS7でパスワードなしのログインを構成する
私たちは、sshが私たちのマシンで構成されている必要があり、Hadoopのは、SSHを使用してノードを管理します。マスターノードはSSH接続を使用してスレーブノードを接続し、開始や停止などの操作を実行します。
マスターがパスワードなしでsshを使用してスレーブと通信できるように、パスワードなしのsshを設定する必要があります。それ以外の場合は、接続の確立ごとに、パスワードを入力する必要があります。
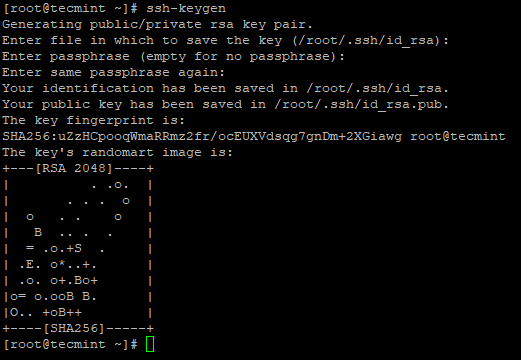
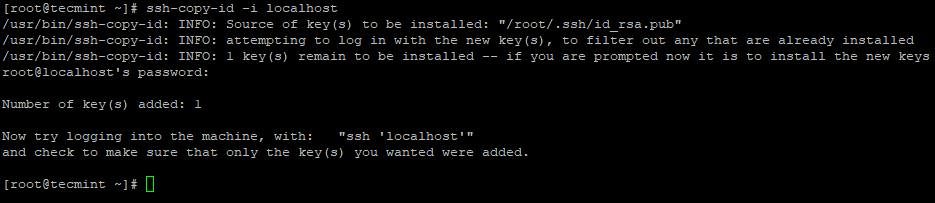
3.サーバーで次のコマンドを使用して、パスワードなしのSSHログインを設定します。
# ssh-keygen # ssh-copy-id -i localhost
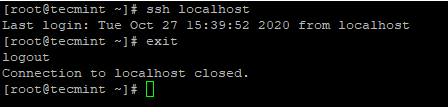
4.パスワードなしのSSHログインを構成した後、再度ログインしてみてください。パスワードなしで接続されます。
# ssh localhost
CentOS7へのHadoopのインストール
5. Apache Hadoop Webサイトにアクセスし、次のwgetコマンドを使用してHadoopの安定版リリースをダウンロードします。
# wget https://archive.apache.org/dist/hadoop/core/hadoop-2.10.1/hadoop-2.10.1.tar.gz # tar xvpzf hadoop-2.10.1.tar.gz
6.次に、図のように、 Hadoop環境変数を~/.bashrcファイルに追加します。
HADOOP_PREFIX=/root/hadoop-2.10.1 PATH=$PATH:$HADOOP_PREFIX/bin export PATH JAVA_HOME HADOOP_PREFIX
7.ファイルの~/.bashrc環境変数を追加した後、ファイルをソースし、次のコマンドを実行してHadoopを確認します。
# source ~/.bashrc # cd $HADOOP_PREFIX # bin/hadoop version
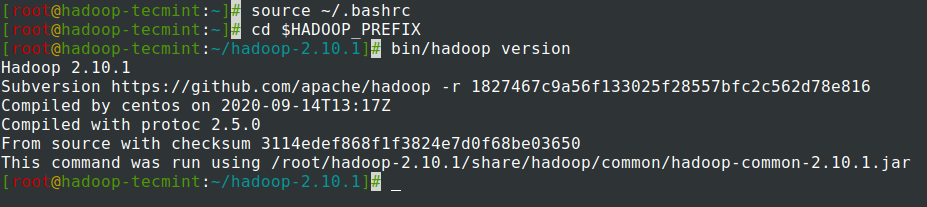
CentOS7でのHadoopの構成
マシンに合わせるには、以下のHadoop構成ファイルを構成する必要があります。 Hadoopでは、各サービスに独自のポート番号とデータを格納するための独自のディレクトリがあります。
- Hadoop構成ファイル– core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
8.まず、図のように、 hadoop-env.shファイルのJAVA_HOMEパスとHadoopパスを更新する必要があります。
# cd $HADOOP_PREFIX/etc/hadoop # vi hadoop-env.sh
ファイルの先頭に次の行を入力します。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0/jre export HADOOP_PREFIX=/root/hadoop-2.10.1
9.次に、 core-site.xmlファイルを変更します。
# cd $HADOOP_PREFIX/etc/hadoop # vi core-site.xml
図のように、 <configuration>タグの間に次のように貼り付けます。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
10. tecmintユーザーのホームディレクトリの下に以下のディレクトリを作成します。これは、 NNおよびDNストレージに使用されます。
# mkdir -p /home/tecmint/hdata/ # mkdir -p /home/tecmint/hdata/data # mkdir -p /home/tecmint/hdata/name
10.次に、 hdfs-site.xmlファイルを変更します。
# cd $HADOOP_PREFIX/etc/hadoop # vi hdfs-site.xml
図のように、 <configuration>タグの間に次のように貼り付けます。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/tecmint/hdata/name</value>
</property>
<property>
<name>dfs .datanode.data.dir</name>
<value>home/tecmint/hdata/data</value>
</property>
</configuration>
11.ここでも、 mapred-site.xmlファイルを変更します。
# cd $HADOOP_PREFIX/etc/hadoop # cp mapred-site.xml.template mapred-site.xml # vi mapred-site.xml
図のように、 <configuration>タグの間に次のように貼り付けます。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
12.最後に、 yarn-site.xmlファイルを変更します。
# cd $HADOOP_PREFIX/etc/hadoop # vi yarn-site.xml
図のように、 <configuration>タグの間に次のように貼り付けます。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
NameNodeを介したHDFSファイルシステムのフォーマット
13.クラスターを開始する前に、 HadoopNNがインストールされているローカルシステムでフォーマットする必要があります。通常、クラスターを最初に開始する前の初期段階で実行されます。
NNをフォーマットすると、NNメタストア内のデータが失われるため、注意が必要です。意図的に必要とされない限り、クラスターの実行中にNNをフォーマットしないでください。
# cd $HADOOP_PREFIX # bin/hadoop namenode -format
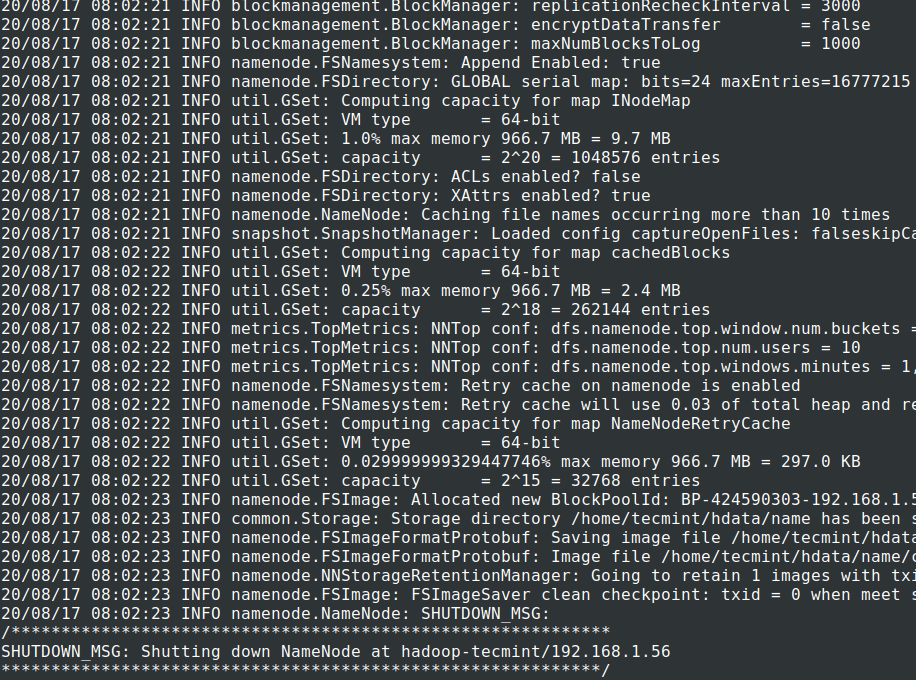
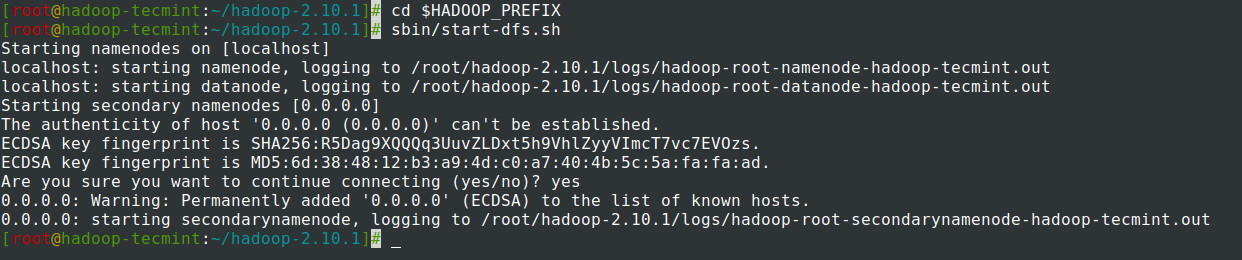
14. NameNodeデーモンとDataNodeデーモンを起動します:(ポート50070 )。
# cd $HADOOP_PREFIX # sbin/start-dfs.sh
15. ResourceManagerデーモンとNodeManagerデーモンを起動します:(ポート8088 )。
# sbin/start-yarn.sh

16.すべてのサービスを停止します。
# sbin/stop-dfs.sh # sbin/stop-dfs.sh
概要
この記事では、 Hadoop疑似ノード(シングルノード)クラスターをセットアップするためのステップバイステップのプロセスを実行しました。 Linuxの基本的な知識があり、次の手順に従うと、クラスターは40分で稼働します。
これは、初心者がHadoopの学習と実践を開始するのに非常に役立ちます。または、このバニラバージョンのHadoopを開発目的で使用できます。リアルタイムクラスターが必要な場合は、少なくとも3台の物理サーバーが必要であるか、複数のサーバーを持つようにクラウドをプロビジョニングする必要があります。