パンダはテーブルをこすりやすくします(<table> タグ)ウェブページ上。 もちろん、DataFrameとして取得した後、さまざまな処理を行って、Excelファイルまたはcsvファイルとして保存することもできます。
この記事では、任意のWebページからテーブルを抽出する方法を学習します。 Webページに複数のテーブルがある場合があるため、必要なテーブルを選択できます。
関連コース: Pythonパンダを使用したデータ分析
パンダのウェブスクレイピング
モジュールをインストールする
モジュールが必要です lxml、 html5lib、 beautifulsoup4。 pipでインストールできます。
1 |
$ pip install lxml html5lib beautifulsoup4 |
pands.read_html()
あなたは機能を使うことができます read_html(url) Webページのコンテンツを取得します。
取得する表はウィキペディアからのものです。 ウィキペディアのPythonページからバージョン履歴テーブルを取得します。
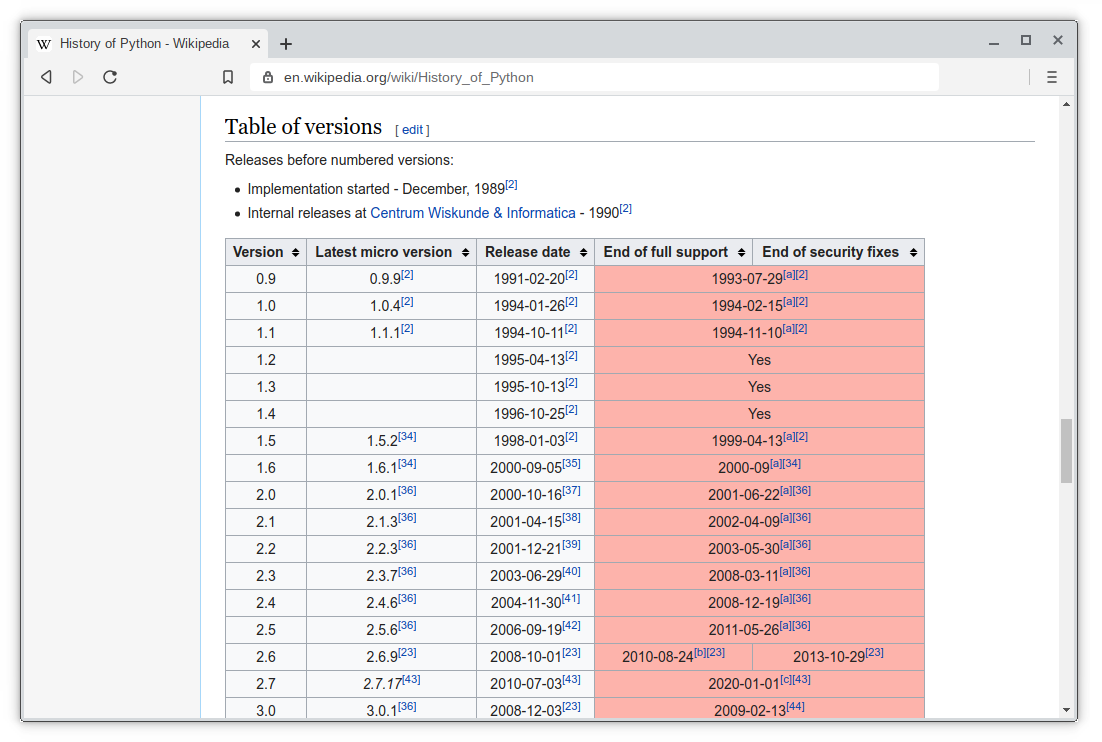
1 |
import pandas as pd |
この出力:
ページにテーブルが1つあるからです。 URLを変更すると、出力が異なります。
テーブルを出力するには:
次のような列にアクセスできます。
1 |
print(dfs[0]['Version']) |
パンダのウェブスクレイピング
DataFrameで取得すると、後処理が簡単になります。 テーブルに多くの列がある場合は、必要な列を選択できます。 以下のコードを参照してください。
1 |
|
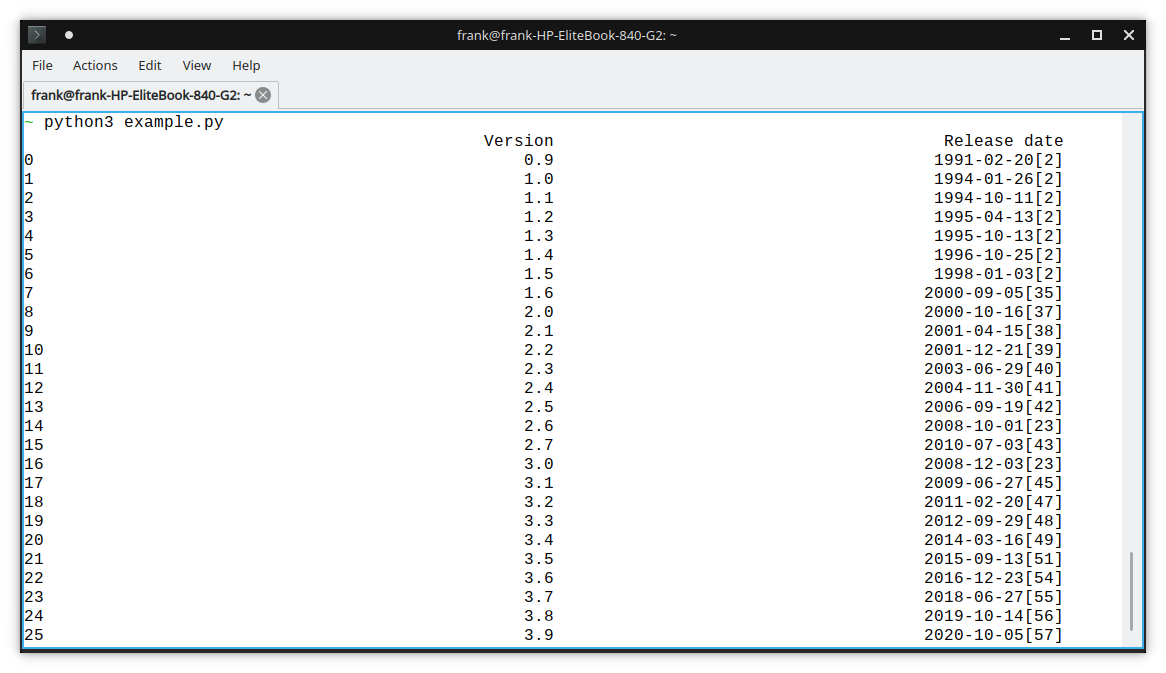
次に、Excelに書き込むか、他のことを行うことができます。
1 |
|
関連コース: Pythonパンダを使用したデータ分析
Hope this helps!
Source link