Python Pandasを使用してExcelファイル(拡張子:.xlsx、.xls)を読み取ります。 ExcelファイルをDataFrameとして読み取るには、パンダを使用します read_excel() 方法。
最初のシート、特定のシート、複数のシート、またはすべてのシートを読むことができます。 Pandasは、これを表形式のような構造であるDataFrame構造に変換します。
関連コース: Pythonパンダを使用したデータ分析
Excel
この記事では、Excelファイルの例を使用します。 作成するプログラムは、ExcelをPythonに読み込みます。
sheet1とsheet2の2枚のシートでExcelファイルを作成します。 MicrosoftExcelやGoogleSheetsなどのExcelサポートプログラムを使用できます。
それぞれの内容は以下のとおりです。
sheet1:
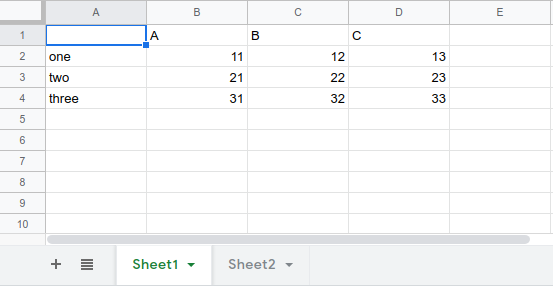
sheet2:
xlrdをインストールします
パンダ。 .read_excel a。)は、内部でxlrdというライブラリを使用します。
xlrdは、PythonでExcelファイル(.xlsx、.xls)を読み取る(入力する)ためのライブラリです。
関連記事:PythonでExcelファイルを読み書きするためにxlrd、xlwtを使用する方法
xlrdがインストールされていない環境でpandas.read_excels()を呼び出すと、次のようなエラーメッセージが表示されます。
ImportError:Excelサポート用にxlrd> = 0.9.0をインストールします
xlrdはpipでインストールできます。 (環境によってはpip3)
エクセルを読む
最初の引数にExcelファイルのパスまたはURLを指定します。
複数のシートがある場合、パンダは最初のシートのみを使用します。
DataFrameとして読み取ります。
1 |
import pandas as pd |
上記のコードは、Excelシートの内容を出力します。
1 |
Unnamed: 0 A B C |
シートを入手
引数sheet_nameを使用して、読み取るシートを指定できます。
番号で指定(0から開始)
1 |
df_sheet_index = pd.read_excel('sample.xlsx', sheet_name=1) |
1 |
# AA BB CC |
シート名で指定:
1 |
df_sheet_name = pd.read_excel('sample.xlsx', sheet_name='sheet2') |
1 |
# AA BB CC |
複数のシートをロードする
また、argumentsheet_nameでリストを指定することもできます。 開始番号0やシート名でもOKです。
指定された番号またはシート名がキーキーであり、データパンダです。 DataFrameは、値が値を持つ順序付き辞書OrderedDictとして読み取られます。
1 |
df_sheet_multi = pd.read_excel('sample.xlsx', sheet_name=[0, 'sheet2']) |
次に、次のように使用できます。
1 |
print(df_sheet_multi[0]) |
すべてのシートを読み込む
sheet_name引数がnoneの場合、すべてのシートが読み取られます。
1 |
df_sheet_all = pd.read_excel('sample.xlsx', sheet_name=None) |
この場合、シート名がキーになります。
1 |
print(df_sheet_all['sheet1']) |
関連コース: Pythonパンダを使用したデータ分析
Hope this helps!
Source link