Apache Hadoopは、クラスター化されたシステムで実行されているさまざまなビッグデータアプリケーションのデータを管理、保存、処理するために使用されるオープンソースフレームワークです。 Javaで書かれており、Cのネイティブコードとシェルスクリプトが含まれています。分散ファイルシステム(HDFS)を使用し、単一サーバーから数千のマシンにスケールアップします。
Apache Hadoopは、次の4つの主要コンポーネントに基づいています。
- Hadoop Common:他のHadoopモジュールが必要とするユーティリティとライブラリのコレクションです。
- HDFS: Hadoop Distributed File Systemとも呼ばれ、複数のノードに分散されます。
- MapReduce:これは、大量のデータを処理するアプリケーションを作成するために使用されるフレームワークです。
- Hadoop YARN:別名Another Resource Negotiatorは、Hadoopのリソース管理レイヤーです。
このチュートリアルでは、Ubuntu 20.04で単一ノードのHadoopクラスターを設定する方法について説明します。
前提条件
- 4 GBのRAMを備えたUbuntu 20.04を実行するサーバー。
- サーバーにrootパスワードが設定されています。
システムパッケージを更新する
開始する前に、システムパッケージを最新バージョンに更新することをお勧めします。次のコマンドで実行できます。
apt-get update -y
apt-get upgrade -yシステムが更新されたら、変更を実装するためにシステムを再起動します。
Javaをインストールする
Apache HadoopはJavaベースのアプリケーションです。したがって、システムにJavaをインストールする必要があります。次のコマンドでインストールできます。
apt-get install default-jdk default-jre -yインストールしたら、次のコマンドを使用して、インストールされているJavaのバージョンを確認できます。
java -version次の出力が表示されます。
openjdk version "11.0.7" 2020-04-14 OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1) OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)
Hadoopユーザーの作成とパスワードなしのSSHのセットアップ
まず、次のコマンドでhadoopという名前の新しいユーザーを作成します。
adduser hadoop次に、hadoopユーザーをsudoグループに追加します
usermod -aG sudo hadoop
次に、hadoopユーザーでログインし、次のコマンドでSSH鍵ペアを生成します。
su - hadoop
ssh-keygen -t rsa次の出力が表示されます。
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:HG2K6x1aCGuJMqRKJb+GKIDRdKCd8LXnGsB7WSxApno hadoop@ubuntu2004 The key's randomart image is: +---[RSA 3072]----+ |..=.. | | O.+.o . | |oo*.o + . o | |o .o * o + | |o+E.= o S | |=.+o * o | |*.o.= o o | |=+ o.. + . | |o .. o . | +----[SHA256]-----+
次に、このキーを承認済みのsshキーに追加し、適切な権限を付与します。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys次に、次のコマンドでパスワードなしのSSHを確認します。
ssh localhostパスワードなしでログインすると、次のステップに進むことができます。
Hadoopをインストールする
まず、hadoopユーザーでログインし、次のコマンドでHadoopの最新バージョンをダウンロードします。
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gzダウンロードが完了したら、次のコマンドでダウンロードしたファイルを抽出します。
tar -xvzf hadoop-3.2.1.tar.gz次に、抽出したディレクトリを/ usr / local /に移動します。
sudo mv hadoop-3.2.1 /usr/local/hadoop次に、次のコマンドでログを保存するディレクトリを作成します。
sudo mkdir /usr/local/hadoop/logs次に、hadoopディレクトリの所有権をhadoopに変更します。
sudo chown -R hadoop:hadoop /usr/local/hadoop次に、Hadoop環境変数を構成する必要があります。 〜/ .bashrcファイルを編集することでそれを行うことができます:
nano ~/.bashrc次の行を追加します。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
終了したら、ファイルを保存して閉じます。次に、次のコマンドで環境変数をアクティブにします。
source ~/.bashrcHadoopを構成する
このセクションでは、単一ノードでHadoopをセットアップする方法を学習します。
Java環境変数の構成
次に、hadoop-env.shでJava環境変数を定義して、YARN、HDFS、MapReduce、およびHadoop関連のプロジェクト設定を構成する必要があります。 広告
まず、次のコマンドを使用して正しいJavaパスを見つけます。
which javac次の出力が表示されます。
/usr/bin/javac
次に、次のコマンドでOpenJDKディレクトリを見つけます。
readlink -f /usr/bin/javac次の出力が表示されます。
/usr/lib/jvm/java-11-openjdk-amd64/bin/javac
次に、hadoop-env.shファイルを編集し、Javaパスを定義します。
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh次の行を追加します。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
次に、Javaxアクティベーションファイルもダウンロードする必要があります。次のコマンドでダウンロードできます。
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar次のコマンドを使用して、Hadoopのバージョンを確認できます。
hadoop version次の出力が表示されます。
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
core-site.xmlファイルの構成
次に、NameNodeのURLを指定する必要があります。これを行うには、core-site.xmlファイルを編集します。 広告
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml次の行を追加します。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
終了したら、ファイルを保存して閉じます。
hdfs-site.xmlファイルの構成
次に、ノードのメタデータ、fsimageファイル、および編集ログファイルを保存する場所を定義する必要があります。 hdfs-site.xmlファイルを編集することでそれを行うことができます。まず、ノードのメタデータを保存するためのディレクトリを作成します。
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfs次に、hdfs-site.xmlファイルを編集して、ディレクトリの場所を定義します。
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml次の行を追加します。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
ファイルを保存して閉じます。
mapred-site.xmlファイルの構成
次に、MapReduce値を定義する必要があります。 mapred-site.xmlファイルを編集して定義できます。
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml次の行を追加します。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
ファイルを保存して閉じます。
yarn-site.xmlファイルを構成する
次に、yarn-site.xmlファイルを編集して、YARN関連の設定を定義する必要があります。
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml次の行を追加します。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
終了したら、ファイルを保存して閉じます。
HDFS NameNodeのフォーマット
次に、Hadoop構成を検証し、HDFS NameNodeをフォーマットする必要があります。
まず、Hadoopユーザーでログインし、次のコマンドでHDFS NameNodeをフォーマットします。
su - hadoop
hdfs namenode -format次の出力が表示されます。
2020-06-07 11:35:57,691 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,692 INFO util.GSet: 0.25% max memory 1.9 GB = 5.0 MB 2020-06-07 11:35:57,692 INFO util.GSet: capacity = 2^19 = 524288 entries 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 2020-06-07 11:35:57,706 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 2020-06-07 11:35:57,710 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 2020-06-07 11:35:57,712 INFO util.GSet: Computing capacity for map NameNodeRetryCache 2020-06-07 11:35:57,712 INFO util.GSet: VM type = 64-bit 2020-06-07 11:35:57,712 INFO util.GSet: 0.029999999329447746% max memory 1.9 GB = 611.9 KB 2020-06-07 11:35:57,712 INFO util.GSet: capacity = 2^16 = 65536 entries 2020-06-07 11:35:57,743 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1242120599-69.87.216.36-1591529757733 2020-06-07 11:35:57,763 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted. 2020-06-07 11:35:57,817 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression 2020-06-07 11:35:57,972 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 398 bytes saved in 0 seconds . 2020-06-07 11:35:57,987 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-06-07 11:35:58,000 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-06-07 11:35:58,003 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2004/69.87.216.36 ************************************************************/
Hadoopクラスターを起動する
まず、次のコマンドでNameNodeとDataNodeを開始します。
start-dfs.sh次の出力が表示されます。
Starting namenodes on [0.0.0.0] Starting datanodes Starting secondary namenodes [ubuntu2004]
次に、次のコマンドを実行して、YARNリソースとノードマネージャーを起動します。
start-yarn.sh次の出力が表示されます。
Starting resourcemanager Starting nodemanagers
次のコマンドでそれらを確認できます。
jps次の出力が表示されます。
5047 NameNode 5850 Jps 5326 SecondaryNameNode 5151 DataNode
Hadoop Webインターフェースへのアクセス
これで、URL http:// your-server-ip:9870を使用してHadoop NameNodeにアクセスできます 。次の画面が表示されます。
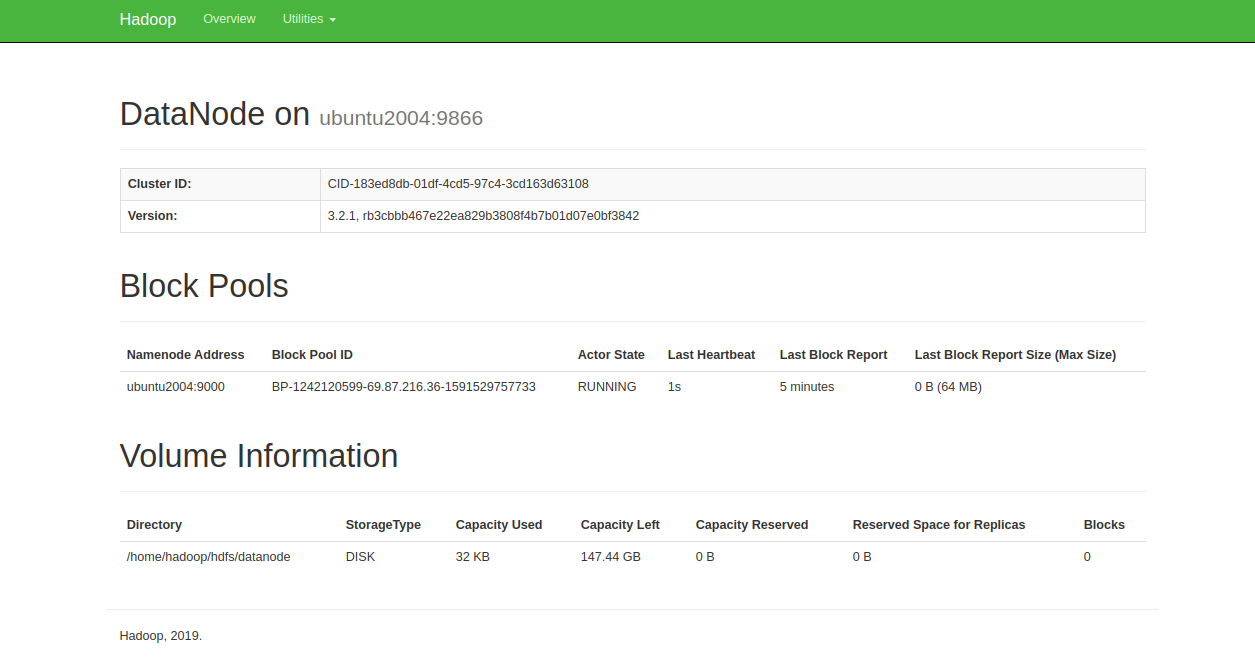
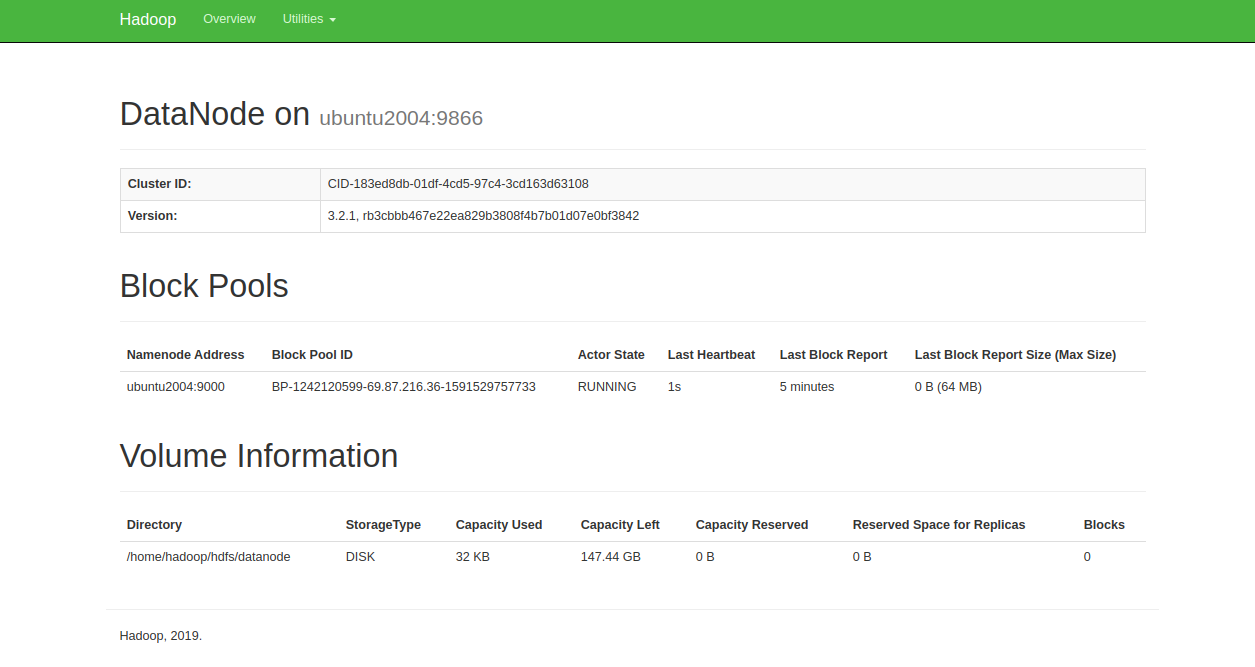
URL http:// your-server-ip:9864を使用して、個々のDataNodeにアクセスすることもできます。次の画面が表示されます。
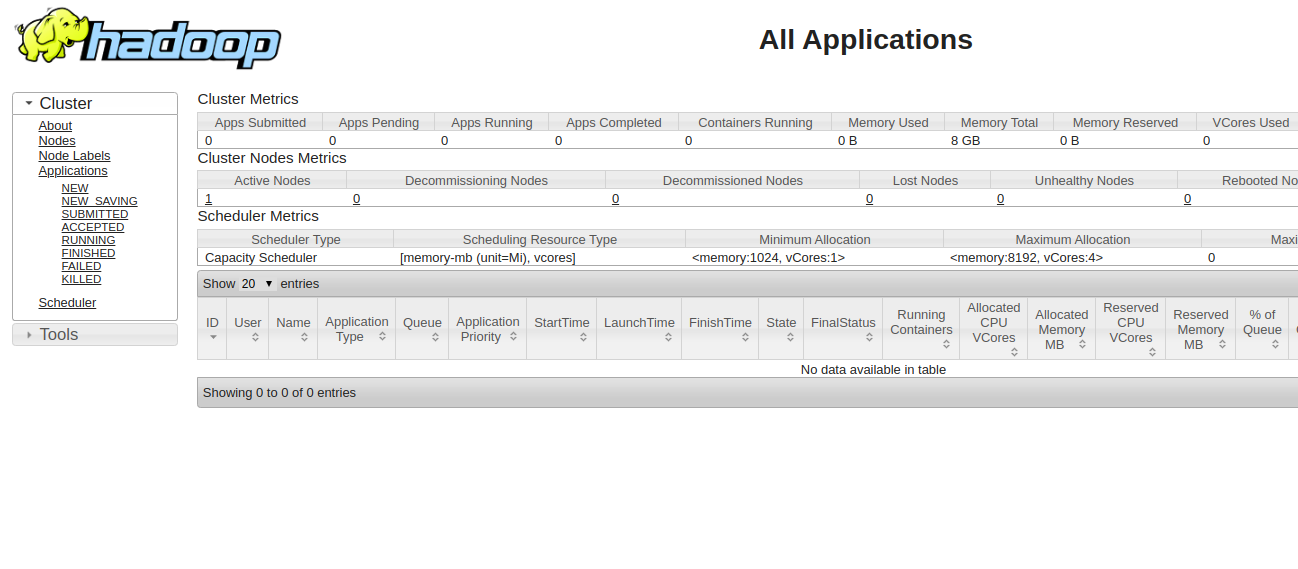
YARNリソースマネージャーにアクセスするには、URL http:// your-server-ip:8088を使用します。次の画面が表示されます。
結論
おめでとう!単一ノードにHadoopが正常にインストールされました。これで、基本的なHDFSコマンドの探索を開始し、完全に分散したHadoopクラスターを設計できます。ご不明な点がございましたら、お気軽にお問い合わせください。