
目次
Apache Spark は、より高速な計算結果を提供するために作成されたオープンソースの分散計算フレームワークです。 これはインメモリ計算エンジンであり、データがメモリ内で処理されることを意味します。
スパーク ストリーミング、グラフ処理、SQL、MLLib用のさまざまなAPIをサポートします。 また、優先言語としてJava、Python、Scala、およびRをサポートします。 Sparkは主にHadoopクラスターにインストールされますが、スタンドアロンモードでSparkをインストールして構成することもできます。
この記事では、インストール方法を見ていきます Apache Spark に Debian そして Ubuntuベースのディストリビューション。
UbuntuにJavaとScalaをインストールする
インストールするには Apache Spark Ubuntuでは、あなたは持っている必要があります Java そして Scala マシンにインストールされています。 最新のディストリビューションのほとんどには、デフォルトでJavaがインストールされており、次のコマンドを使用して確認できます。
$ java -version

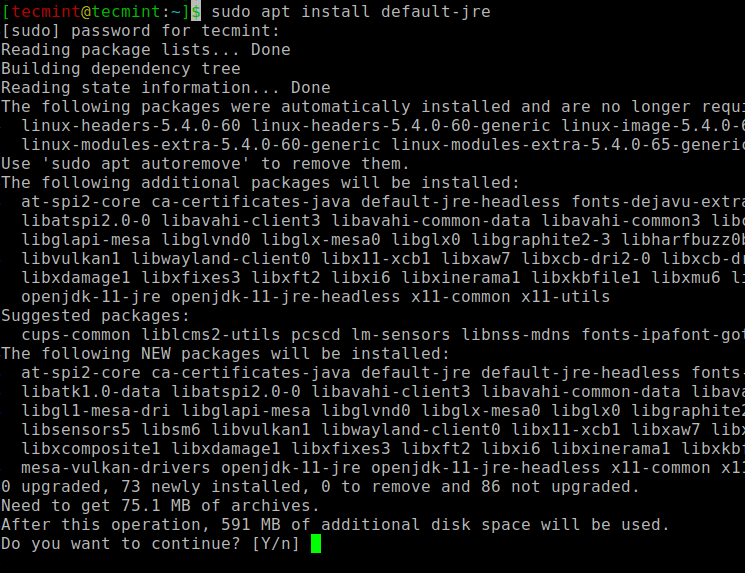
出力がない場合は、UbuntuにJavaをインストールする方法に関する記事を使用してJavaをインストールするか、次のコマンドを実行してUbuntuおよびDebianベースのディストリビューションにJavaをインストールできます。
$ sudo apt update $ sudo apt install default-jre $ java -version
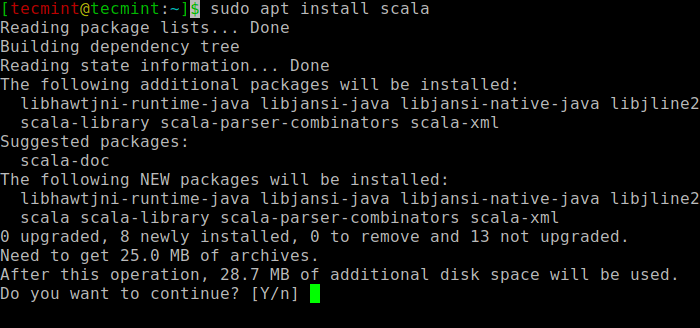
次に、インストールできます Scala 次のコマンドを実行してaptリポジトリからscalaを検索し、インストールします。
$ sudo apt search scala ⇒ Search for the package $ sudo apt install scala ⇒ Install the package
のインストールを確認するには Scala、次のコマンドを実行します。
$ scala -version Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
UbuntuにApacheSparkをインストールする
今、公式に行きます ApacheSparkダウンロードページ この記事の執筆時点で最新バージョン(つまり3.1.1)を入手してください。 または、wgetコマンドを使用して、ターミナルに直接ファイルをダウンロードすることもできます。
$ wget https://apachemirror.wuchna.com/spark/spark-3.1.1/spark-3.1.1-bin-hadoop2.7.tgz
次に、ターミナルを開き、ダウンロードしたファイルが配置されている場所に切り替え、次のコマンドを実行してApache Sparktarファイルを抽出します。
$ tar -xvzf spark-3.1.1-bin-hadoop2.7.tgz
最後に、抽出したものを移動します スパーク ディレクトリから / opt ディレクトリ。
$ sudo mv spark-3.1.1-bin-hadoop2.7 /opt/spark
Sparkの環境変数を構成する
今、あなたはあなたの中にいくつかの環境変数を設定する必要があります 。プロフィール スパークを開始する前にファイルします。
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile $ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile $ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
これらの新しい環境変数がシェル内で到達可能であり、Apache Sparkで使用可能であることを確認するには、次のコマンドを実行して最近の変更を有効にすることも必須です。
$ source ~/.profile
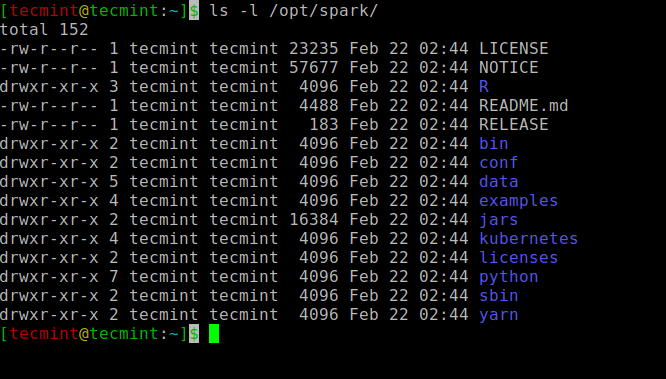
サービスを開始および停止するためのすべてのスパーク関連のバイナリは、 sbin フォルダ。
$ ls -l /opt/spark
UbuntuでApacheSparkを起動します
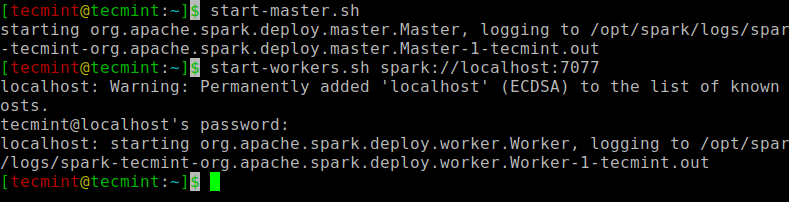
次のコマンドを実行して、 スパーク マスターサービスとスレーブサービス。
$ start-master.sh $ start-workers.sh spark://localhost:7077
サービスが開始されたら、ブラウザに移動して、次のURLアクセススパークページを入力します。 このページから、私のマスターとスレーブのサービスが開始されていることがわかります。
http://localhost:8080/ OR http://127.0.0.1:8080
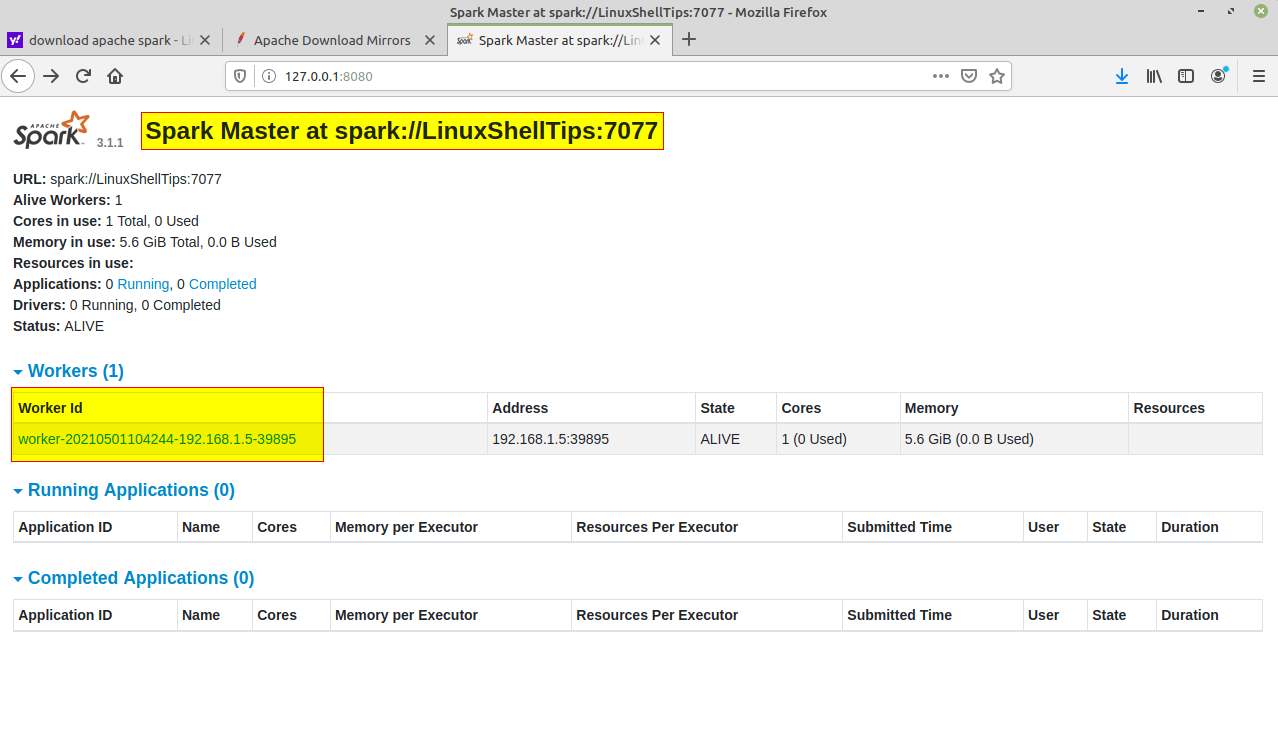
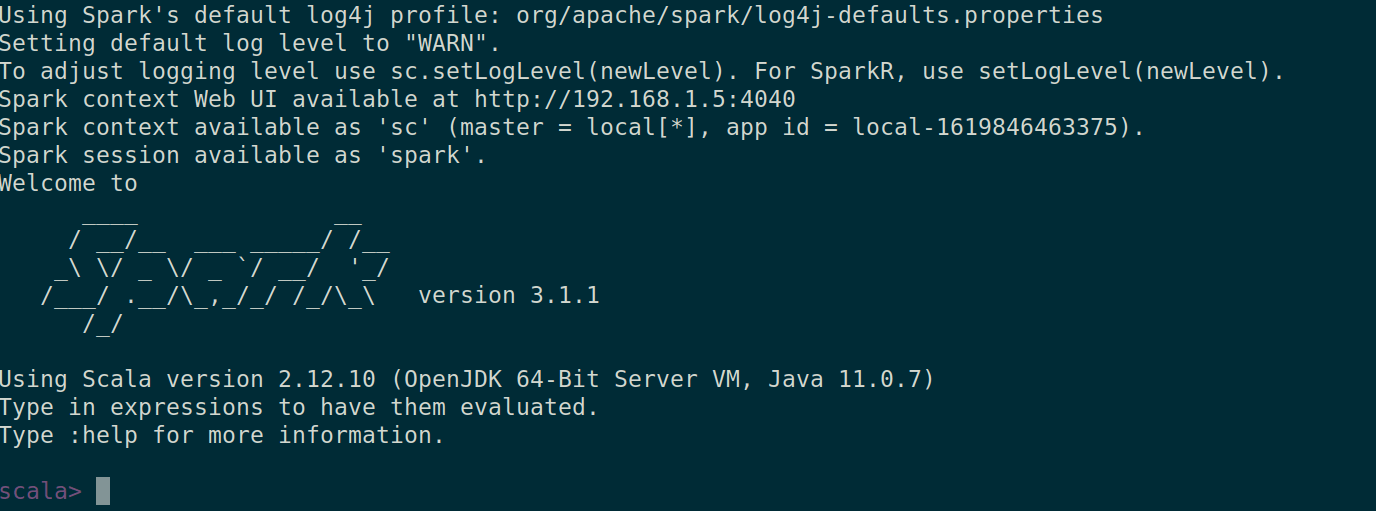
かどうかを確認することもできます スパークシェル を起動することで正常に動作します スパークシェル コマンド。
$ spark-shell
この記事は以上です。 もうすぐ興味深い記事をお届けします。
Hope this helps!

