目次
Apache Kafkaは、Apache SoftwareFoundationによって開発されたオープンソースの分散イベントストリーミングプラットフォームです。 これはScalaとJavaプログラミング言語で書かれています。 Kafkaは、Javaをサポートする任意のプラットフォームにインストールできます。
このチュートリアルでは、Ubuntu 20.04 LTSLinuxシステムにApacheKafkaをインストールするためのステップバイステップのチュートリアルについて説明しました。 また、Kafkaでトピックを作成し、プロデューサーノードとコンシューマーノードを実行する方法も学習します。
前提条件
Ubuntu 20.04Linuxシステムへのsudo特権アカウントアクセスが必要です。
ステップ1-Javaのインストール
Apache Kafkaは、プラットフォームでサポートされているすべてのJavaで実行できます。 UbuntuシステムでKafkaをセットアップするには、最初にJavaをインストールする必要があります。 ご存知のように、Oracle javaは現在市販されているため、オープンソースバージョンのOpenJDKを使用しています。
以下のコマンドを実行して、公式PPAからシステムにOpenJDKをインストールします。
sudo apt update sudo apt install default-jdk
現在アクティブなJavaバージョンを確認します。
java --version openjdk version "11.0.9.1" 2020-11-04 OpenJDK Runtime Environment (build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04) OpenJDK 64-Bit Server VM (build 11.0.9.1+1-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)ステップ2–最新のApacheKafkaをダウンロードする
公式からApacheKafkaバイナリファイルをダウンロードします ダウンロード ウェブサイト。 近くのミラーを選択してダウンロードすることもできます。
wget http://www-us.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
次に、アーカイブファイルを抽出します
tar xzf kafka_2.13-2.7.0.tgz mv kafka_2.13-2.7.0 /usr/local/kafka
ステップ3–Systemdユニットファイルの作成
次に、ZookeeperおよびKafkaサービス用のsystemdユニットファイルを作成する必要があります。 これは、Kafkaサービスを簡単に開始/停止するのに役立ちます。
まず、Zookeeperのsystemdユニットファイルを作成します。
vim /etc/systemd/system/zookeeper.service
そして、次のコンテンツを追加します。
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
ファイルを保存して閉じます。
次に、Kafkaサービスのsystemdユニットファイルを作成するには:
vim /etc/systemd/system/kafka.service
以下のコンテンツを追加してください。 必ず正しい設定をしてください JAVA_HOME システムにインストールされているJavaによるパス。
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64" ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
ファイルを保存して閉じます。
systemdデーモンをリロードして、新しい変更を適用します。
systemctl daemon-reload
ステップ4–KafkaおよびZookeeperサービスを開始する
まず、ZooKeeperサービスを開始してから、Kafkaを開始する必要があります。 systemctlコマンドを使用して、単一ノードのZooKeeperインスタンスを開始します。
sudo systemctl start zookeeper
次に、Kafkaサーバーを起動し、実行ステータスを表示します。
sudo systemctl start kafka sudo systemctl status kafka
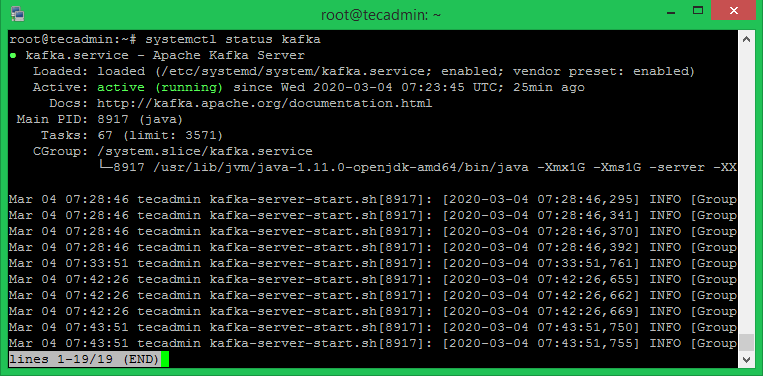
全部終わった。 Kafkaのインストールは正常に完了しました。 このチュートリアルの一部は、Kafkaサーバーの操作に役立ちます。
ステップ5–Kafkaでトピックを作成する
Kafkaは、それを処理するための複数のビルド済みシェルスクリプトを提供します。 まず、単一のレプリカを持つ単一のパーティションで「testTopic」という名前のトピックを作成します。
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic Created topic testTopic.
レプリケーション係数は、作成されるデータのコピーの数を示します。 単一のインスタンスで実行しているため、この値を1のままにします。
データを分割するブローカーの数としてパーティションオプションを設定します。 単一のブローカーで実行しているため、この値を1に保ちます。
上記と同じコマンドを実行して、複数のトピックを作成できます。 その後、以下のコマンドを実行すると、Kafkaで作成されたトピックを確認できます。
bin/kafka-topics.sh --list --zookeeper localhost:2181 [output] testTopic
または、トピックを手動で作成する代わりに、存在しないトピックが公開されたときにトピックを自動作成するようにブローカーを構成することもできます。
ステップ6–Kafkaでメッセージを送受信する
「プロデューサー」は、Kafkaにデータを入力するプロセスです。 Kafkaには、ファイルまたは標準入力から入力を受け取り、それをメッセージとしてKafkaクラスターに送信するコマンドラインクライアントが付属しています。 デフォルトのKafkaは、各行を個別のメッセージとして送信します。
プロデューサーを実行してから、コンソールにいくつかのメッセージを入力してサーバーに送信しましょう。
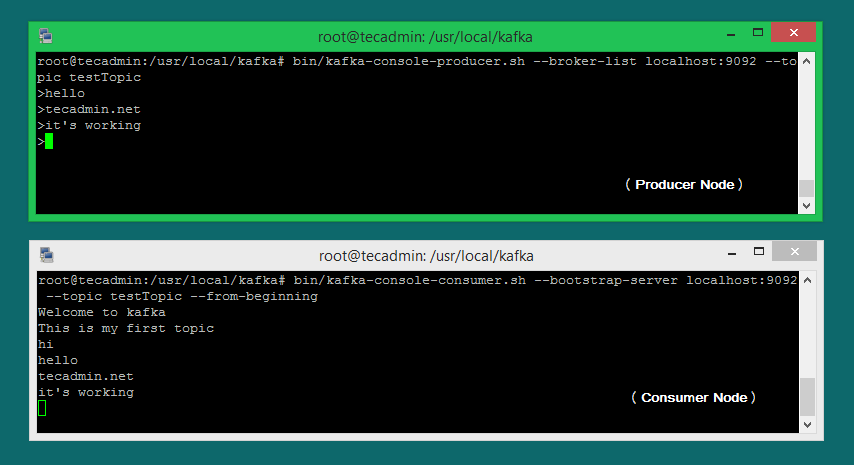
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic >Welcome to kafka >This is my first topic >
このコマンドを終了するか、この端末を実行したままにして、さらにテストすることができます。 次のステップで、Kafkaコンシューマープロセスへの新しいターミナルを開きます。
ステップ7–Kafkaコンシューマーの使用
Kafkaには、Kafkaクラスターからデータを読み取り、メッセージを標準出力に表示するコマンドラインコンシューマーもあります。
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning Welcome to kafka This is my first topic
ここで、別の端末でKafkaプロデューサー(ステップ#6)をまだ実行している場合。 そのプロデューサー端末にテキストを入力するだけです。 コンシューマー端末にすぐに表示されます。 以下のKafkaの生産者と消費者のスクリーンショットを参照してください。
結論
このチュートリアルは、UbuntuシステムにApacheKafkaサービスをインストールして構成するのに役立ちました。 さらに、Kafkaサーバーで新しいトピックを作成し、ApacheKafkaを使用してサンプルの本番プロセスとコンシューマープロセスを実行する方法を学びました。
Hope this helps!